Just a collection of handy bash scripts for working with PDFs. https://github.com/alistaircol/pdf-sh
There’s nothing that these scripts do that can’t be done inside browsers PDF print utilities (maybe except cat or other PDF viewers, but this way for me is a little less cluttered.
Warning: not the best bash code ever. Probably doesn’t handle spaces/quotes in file names correctly, etc.
I’ll probably update this article with better bash and screenshots.
I use the following tools in these scripts:
pdf-cat.sh
Append multiple documents to a new file.
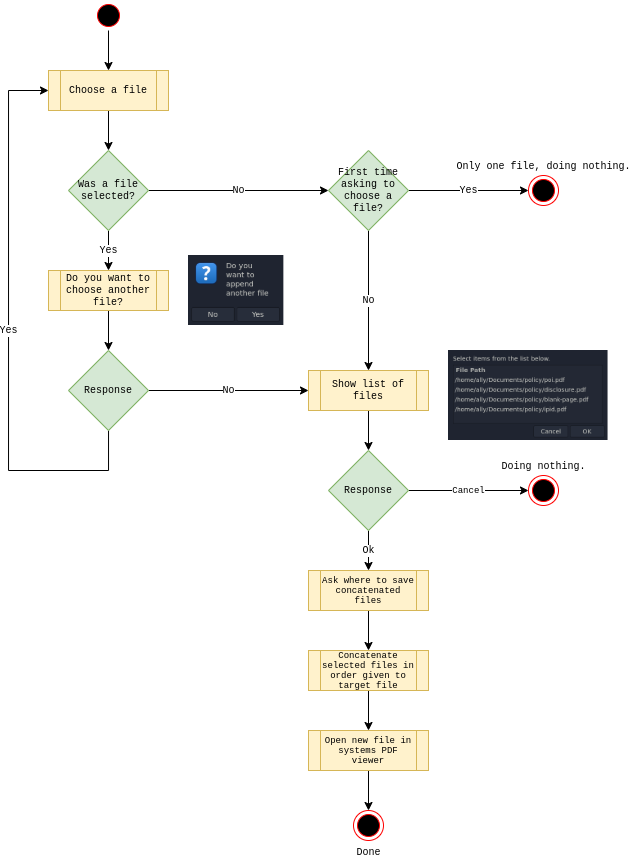
#!/usr/bin/env bash
# http://jamesslocum.com/post/61904545275
FILES=()
STOP=0
echo "Append documents together, order is important!"
PDF_SOURCE=$(zenity \
--file-selection \
--file-filter='PDF files (pdf) | *.pdf' \
--title="Select a PDF file" \
2> /dev/null
)
INITIAL_PDF_SOURCE_CHOSEN=$?
if [ $INITIAL_PDF_SOURCE_CHOSEN -ne "0" ]; then
echo "No source given, bye"
exit 0
fi
echo "SOURCE: ${PDF_SOURCE}"
FILES+=("${PDF_SOURCE}")
while [ $STOP -eq "0" ]; do
# Y = 0
# N = 1
zenity \
--question \
--text="Do you want to append another file" \
--ok-label="Yes" \
--cancel-label="No" \
2> /dev/null
APPEND_ANOTHER=$?
if [ $APPEND_ANOTHER -ne "0" ]; then
STOP=1
else
PDF_SOURCE=$(zenity \
--file-selection \
--file-filter='PDF files (pdf) | *.pdf' \
--title="Select a PDF file" \
2> /dev/null
)
echo "SOURCE: ${PDF_SOURCE}"
FILES+=("${PDF_SOURCE}")
fi
done
if [ ${#FILES[@]} -eq "1" ]; then
echo "Only one file, doing nothing."
exit 0
fi
# https://askubuntu.com/a/844278/762631
LIST_COLUMN_NAMES=(--column="File Path")
zenity \
--list \
--title="Files to append" "${LIST_COLUMN_NAMES[@]}" "${FILES[@]}" \
2> /dev/null
PROCEED=$?
if [ $PROCEED -ne "0" ]; then
echo "Doing nothing."
else
echo "Concatting!"
PDF_TARGET=$(zenity \
--file-selection \
--file-filter='PDF files (pdf) | *.pdf' \
--title="Select a target file to save combined documents" \
--save \
--confirm-overwrite \
2> /dev/null
)
echo "TARGET: ${PDF_TARGET}"
pdftk "${FILES[@]}" cat output ${PDF_TARGET}
echo "Done!"
xdg-open $PDF_TARGET
fi
pdftk "${FILES[@]}" cat output ${PDF_TARGET} is the main thing, and can pass list of files from stdin which is probably the better option, but not as fun when you need this very infrequently. Might add this as an aside later, since I think it would be a good thing for me to learn.
pdf-cut.sh
Cut/extract pages from a document to a new file.
This is one of the things most easily accomplishable and more versatile from the print to file system dialogs from browser/pdf viewer. I got carried away one day with this.
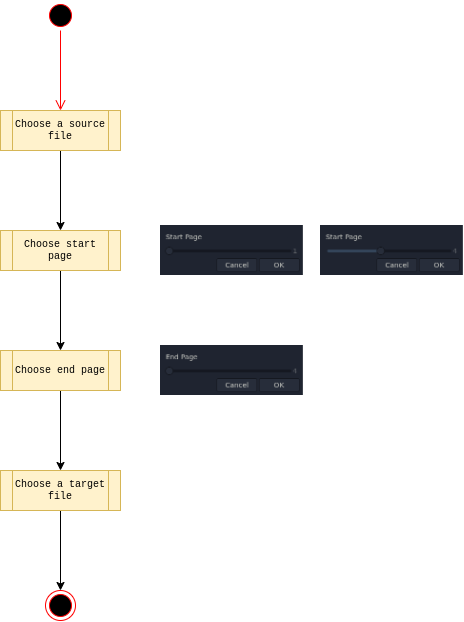
#!/usr/bin/env bash
echo "Please select the PDF file you wish to slice"
PDF_SOURCE=$(zenity \
--file-selection \
--file-filter='PDF files (pdf) | *.pdf' \
--title="Select a PDF file to slice" \
2> /dev/null
)
PDF_SOURCE_VERSION=$(pdfinfo $PDF_SOURCE | grep 'PDF version')
echo "Source PDF: ${PDF_SOURCE}"
echo "Source PDF: ${PDF_SOURCE_VERSION}"
PDF_SOURCE_PAGES=$(pdfinfo $PDF_SOURCE | grep "Pages:" | awk '{print $2}')
echo "Please select page number you want to start"
PDF_SOURCE_PAGE_START=$(zenity \
--scale \
--min-value=1 \
--max-value=$PDF_SOURCE_PAGES \
--step=1 \
--value=1 \
--text="Start Page" \
2> /dev/null
)
echo "Please select page number you want to end"
PDF_SOURCE_PAGE_END=$(zenity \
--scale \
--min-value=$PDF_SOURCE_PAGE_START \
--max-value=$PDF_SOURCE_PAGES \
--step=1 \
--value=$PDF_SOURCE_PAGE_START \
--text="End Page" \
2> /dev/null
)
echo "Num pages: ${PDF_SOURCE_PAGES}"
echo "Num pages: ${PDF_SOURCE_PAGE_START}"
echo "Num pages: ${PDF_SOURCE_PAGE_END}"
echo "Please file you want to save pages ${PDF_SOURCE_PAGE_START} - ${PDF_SOURCE_PAGE_END}"
PDF_TARGET=$(zenity \
--file-selection \
--file-filter='PDF files (pdf) | *.pdf' \
--title="Select a file to save source PDF pages ${PDF_SOURCE_PAGE_START} - ${PDF_SOURCE_PAGE_END}" \
--save \
--confirm-overwrite \
2> /dev/null
)
pdftk "${PDF_SOURCE}" cat $PDF_SOURCE_PAGE_START-$PDF_SOURCE_PAGE_END output $PDF_TARGET
xdg-open $PDF_TARGET
echo "Done!"
pdf-convert.sh
Converts to PDF version 1.4 - this is because when working with TCPDF/FPDI/etc. don’t support later versions, like 1.7.
Don’t think this really merits a diagram or any screenshots. It’s just a couple of file selectors - one to select source file, and a second for the target (converted) file.
Maybe I’ll add option for there to be flags (or just args) to specify the source and target rather than a GUI. Not terribly practical because the underlying command is fairly simple.
#!/usr/bin/env bash
# https://askubuntu.com/a/488354/762631
echo "Please select the PDF file you wish to convert to PDF Version 1.4"
PDF_SOURCE=$(zenity \
--file-selection \
--file-filter='PDF files (pdf) | *.pdf' \
--title="Select a PDF file to convert to PDF Version 1.4" \
2> /dev/null
)
PDF_SOURCE_VERSION=$(pdfinfo $PDF_SOURCE | grep 'PDF version')
echo "Source PDF: ${PDF_SOURCE}"
echo "Source PDF: ${PDF_SOURCE_VERSION}"
PDF_TARGET=$(zenity \
--file-selection \
--file-filter='PDF files (pdf) | *.pdf' \
--title="Select a file to save source PDF to PDF Version 1.4" \
--save \
--confirm-overwrite \
2> /dev/null
)
PDF_TARGET_VERSION="1.4"
echo "Target PDF: ${PDF_TARGET}"
echo "Target PDF: PDF version: ${PDF_TARGET_VERSION}"
echo ""
echo "Converting!"
gs \
-sDEVICE=pdfwrite \
-dCompatibilityLevel=$PDF_TARGET_VERSION \
-o "${PDF_TARGET}" \
"${PDF_SOURCE}"
echo "Done!"
Aside
Might be good idea to adapt file paths from stdin, maybe will make a repo for this, but probably won’t.